写给完全没接触过 LLM 内部细节的朋友。我尽量不写公式,但会带你”看见”模型在做什么。

0. 为什么要从一个问题开始
你在 ChatGPT 里输入一句”帮我写一首关于秋天的短诗”,它回了你一段流畅的文字。
这件事在你看来是”对话”。但在模型看来,它做的事情只有一件:预测下一个 token。
这篇文章就围绕这一句话展开。我们会一步步拆开 LLM:它怎么把中文变成”它能理解的东西”(token),它怎么”记住上下文”(context window),它怎么在生成下一个字的时候”看一眼”前面所有内容(attention),它用什么样的”骨架”组织这些机制(Transformer),现在学术界和工业界又在骨架上做了哪些改造(Mamba、MoE、Flash Attention),最后你会看到——所谓”Prompt 工程”不是花拳绣腿,而是给这个机制一个”更合理的输入协议”。
读完你应该能回答这几个问题:
- 为什么 ChatGPT 的”上下文”是有限的,超过会”失忆”?
- 为什么”上下文越长,模型越贵”这件事不是营销话术?
- 为什么把重要信息放在开头或结尾比放在中间好?
- GPT-4 和 Claude 3.5 内部到底用了什么?
- “MoE”、“RAG”、“Few-shot”、“CoT”这些词到底在说什么?
1. Transformer:2017 年那篇论文改变了一切
1.1 故事起点:Google 翻译团队想做一件”看似不可能”的事
2017 年之前,主流的机器翻译模型都靠 RNN(循环神经网络)这种”一个字一个字读”的思路。这种思路有个大问题:句子一长,前面的信息就被”稀释”了,模型很难把开头和结尾联系起来——就像让你背一篇 5000 字的文章,背到最后一段的时候,开头写了什么你早忘了。
Google Brain 那帮人的论文 Attention Is All You Need(“注意力就是你所需要的一切”)提出了一个大胆的方案:扔掉循环结构,让每个位置的字直接”看”所有其他位置的字。这就是 Transformer。
1.2 一个生活化的比喻:开会的隐喻
想象你坐在一个会议室里,听同事讲一段很长的项目背景。
RNN 的方式 = 你只能听到上一位发言者的话,再听下一位就要靠记忆传递。每一个人发言时,前面所有人说的话都已经变成了模糊印象。
Transformer 的方式 = 在场的每个人都面前放着一块白板,可以随时转头看任何人、问任何人”你刚才说的那句话是什么意思”。任何时候,你都能从所有发言者那里直接拿到最相关的信息。
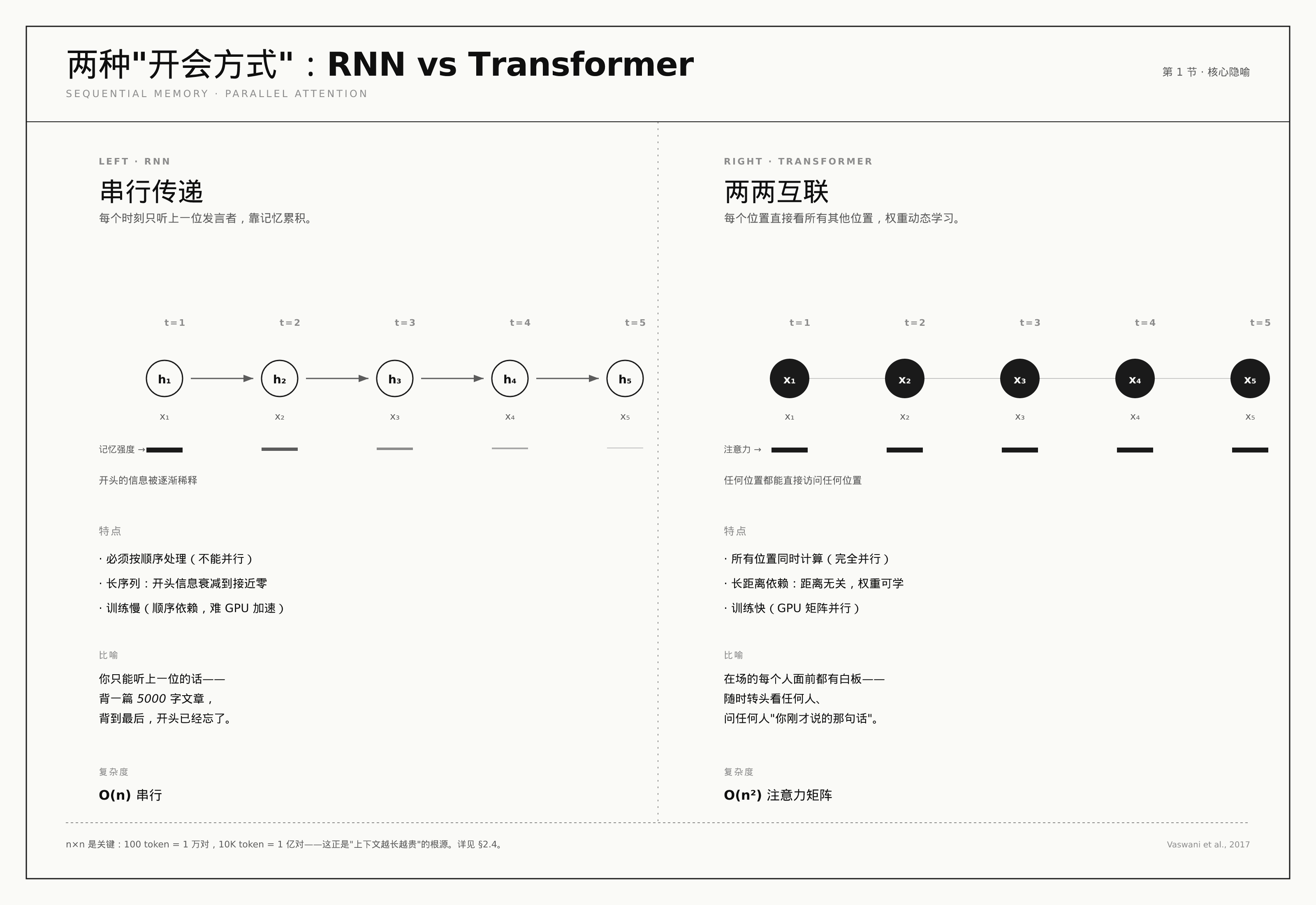
这个”随时转头看任何人、问任何人”的机制,就叫 attention(注意力)。
具体说,模型在读一句话时,对每一个词,都会算一个分数——“这个位置和当前我正在读的这个位置有多相关”。然后把注意力集中在那些高分的词上。这个分数是动态算出来的,不是人预设的,所以模型可以”自动学会”在读”猫”这个词时,去看前面”捉”和”老鼠”。
1.3 三个绕不开的工程细节
如果只记三件事:
第一,位置编码。 Transformer 本身是”无序”的——它处理一句话时,并不天然知道”猫咬狗”和”狗咬猫”的顺序不同。所以必须给每个位置一个”位置编号”。原始论文用了正弦余弦函数生成位置编码,简单说就是给每个位置发一张”有特征的工牌”。
第二,多头注意力。 不只做一次 attention,而是同时做 8 次、16 次、32 次,每次关注不同的”关系维度”。比如一个头可能关注”动词-主语”关系,另一个关注”形容词-名词”关系,最后把所有人的意见汇总。
第三,残差连接 + LayerNorm。 这两个看起来无聊,实际上是让几十层、上百层的网络能稳定训练的关键。原理简单说就是让”信息能抄近道绕过某些层”,避免训练过程中梯度消失——你可以理解为:会议开到最后声音失真了,但有人直接拍桌子喊”按我刚才说的原话做”,把信息救回来。
1.4 一句话总结 Transformer
它把”理解一句话”这件事,改写成了”对所有词两两算相似度 + 加权汇聚 + 前馈变换”的并行流水线。
这句话抽象,但你后面会看到,所有 LLM 变体——GPT、BERT、T5、Llama、Qwen、Claude——都是这个基本骨架的变体或扩展。
1.5 关键公式(可跳过,给想看推导的朋友)
如果你对数学不感冒,直接跳到下一节。这一节是给”想看 attention 到底在算什么”的人准备的。
(1)Scaled dot-product attention —— 一次”互相看一眼”的数学表达
逐项翻译:
- 都是从同一段文字里派生出来的矩阵,三者形状完全一样——可以理解为同一段文字被”投影”成三种不同的”观察视角”。
- (Query)= 当前词发出的”我想找什么”的信号
- (Key)= 每个位置上”我能被搜到什么”的标签
- (Value)= 每个位置上”我能贡献什么内容”的具体信息
- = 用 Q 跟所有 K 做点积,得到一个 的相似度矩阵。
- 除以 ( 是 key 的维度)= 防止点积数值过大,让 softmax 的梯度不会消失。
- = 把每一行归一化成”加起来等于 1”的概率分布。
- 乘以 = 用归一化后的权重对所有 value 做加权求和。
一句白话总结:“用每个位置的 query,去跟所有 key 算亲密度,再按亲密度把 value 加权求和。”
(2)Multi-head attention —— 同时开多组会议
个 head 各自带一套独立的 投影矩阵,相当于让模型同时从 个不同的”子空间”观察 token 之间的关系,最后把结果拼起来再投影回去。
一个 head 可能专门捕捉”动词-主语”关系,另一个可能捕捉”形容词-名词”关系,还有的可能捕捉”长距离引用”关系。
(3)Positional encoding —— 给每个位置发一张有特征的工牌
原始 Transformer 用的固定正弦/余弦编码:
直觉:不同维度 用不同频率,模型既能学绝对位置,也能学相对偏移(因为 ,两个位置的差可以被另一个三角函数表达)。
现代 LLM 大多改用 RoPE(旋转位置编码) 或 ALiBi(线性偏置),核心目的都是同一个:让模型”知道每个 token 在序列里的位置”。
(4)残差 + LayerNorm —— 让几十层深的网络还能训练
每一层不直接变换 ,而是变换一个”增量 “,再把 本身抄近道绕过这层。这样梯度能从顶层直接流到底层,训练上百层的网络也不会”梯度消失”。
2. token、context window、attention:这三个概念是一回事
这一节是很多人学 LLM 时最容易混淆的地方。我用一个具体场景把它们串起来。
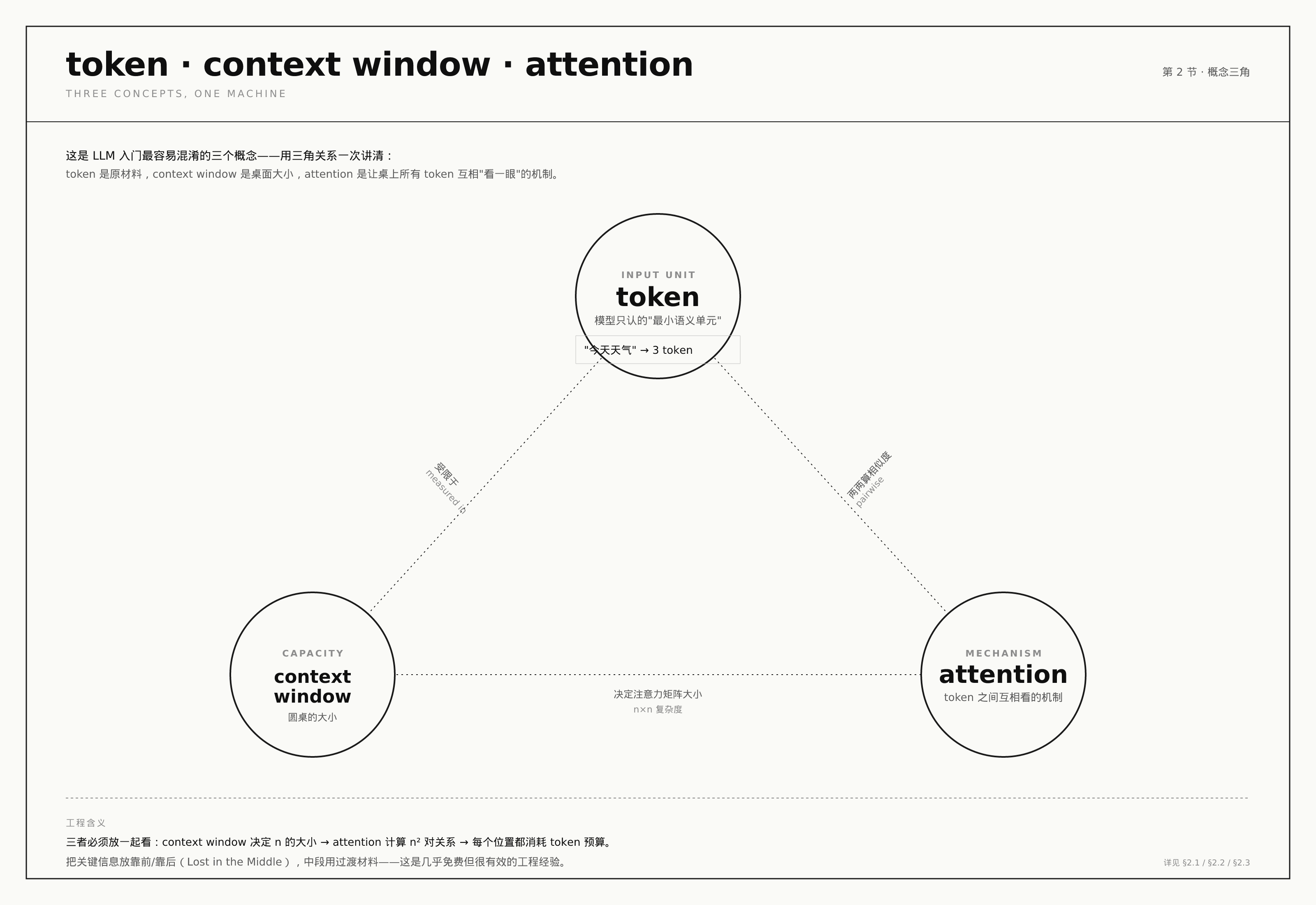
2.1 你看到的”字”,不是模型看到的”字”
你在 ChatGPT 输入”今天天气真好”,屏幕上看到 6 个字。
但模型真正看到的不是 6 个字,而是一串编号——比如 [1012, 8872, 8723, 1963]。每一个编号对应一个”token”。
token 是什么? 它是模型训练时定好的”最小语义单元”。模型只认 token,不认”字”也不认”词”。
怎么把字变成 token? 靠的是分词器(tokenizer),主流方法是 BPE、WordPiece、Unigram(都是子词分词算法)。它们的核心思路都一样:在”字太细、词太粗”之间找平衡。
具体说:
- 高频常用词(“the”、“今天”)通常保留为一个 token。
- 低频词、复合词会被拆成多个 token。比如
playing可能拆成play+ing;unhappiness可能拆成un+happiness。 - 中日韩文本因为没有空格,分词更复杂——这意味着同样一段中文,在 GPT 和 Claude 里的 token 数可能差很多。
为什么这件事重要? 因为模型所有的”上下文长度限制”——比如”上下文 128K”、“上下文 200K”——指的都是 token 数,不是字数。这意味着同一段中文提示词,在不同模型里能塞进去的”份量”不一样。
2.2 context window:模型能”同时看到”的 token 数量
context window(上下文窗口)就是模型在一次对话中能”同时看到”的 token 总数。
把它理解成一个 圆桌:
- 桌子大小是固定的(= context window,比如 128K token)。
- 你和模型的对话历史、你的 system prompt、你塞进上下文的文档、模型之前生成的回复,全都摊在这张桌子上。
- 当桌子摆满了,最早的内容就被”挤出桌外”——模型再也看不到了。
- 这就是为什么 ChatGPT 在对话很长时”忘了开头说过什么”。
一个具体的数字感受:Claude 3.5 Sonnet 的 context window 是 200K token,大约相当于 15 万个英文单词或 50 万个中文字。这听起来很多,但要注意——这不是”白嫖”,每多塞一个 token,模型推理的算力就上升一截(后面会解释为什么)。
2.3 attention:token 之间两两”互相看一眼”的机制
回到刚才那个会议比喻。
当模型在生成第 5 个 token 时,它会回头”看”前面 1-4 号 token,对每一个算一个相似度分数。这个分数决定了”我应该把多少注意力放在前面这个词上”。
标准 Transformer 的 attention 是 两两相连 的:如果序列有 n 个 token,就要算 n×n 个相似度。
这个 n×n 是关键。
当 n=100:1 万对,还算轻松。 当 n=1000:100 万对,还行。 当 n=10000:1 亿对,开始吃力。 当 n=100000:100 亿对,普通 GPU 跑不动。
这就是为什么”上下文越长,模型越慢”的根源——不是因为模型”变笨”了,而是因为 attention 矩阵的体积按 token 数的平方膨胀。
一个对实际工作有指导意义的工程经验是:
能放进 100K 上下文,不等于模型能”用好”100K 上下文。
2023 年斯坦福和 Princeton 的一项研究(论文叫 Lost in the Middle)发现:把关键信息放在 prompt 的开头或结尾,模型表现最好;放在中间,即使上下文只有几千 token,性能也会明显下降。
这个发现的工程含义很直接——写长 prompt 时,把关键约束、关键问题、关键数据放在靠前或靠后位置,中间用过渡内容填充,是几乎免费的优化。
2.4 复杂度公式(给想看数字背后的来源的朋友)
(1)Self-attention 的时间和空间复杂度
是序列长度(token 数), 是每个 token 的向量维度(通常是 64-128)。
直觉:两两算相似度, 个 token 要算 个相似度值。
(2)几个常见近似路线的复杂度对比
| 注意力机制 | 复杂度 | 代表工作 |
|---|---|---|
| Dense self-attention | 原始 Transformer | |
| Sliding window | Mistral、Longformer | |
| Global + local | Longformer( = global tokens) | |
| LSH attention | Reformer | |
| Linear attention | Performer、Linear Transformer | |
| State-space (Mamba) | Mamba(理论上) | |
| Flash Attention(实现层优化) | 但 IO | FlashAttention-1/2/3 |
注意最后一行:Flash Attention 表面上还是 (数学完全等价),但通过把中间结果留在 GPU 高速 SRAM 里,实际 IO 访问从 降到 。这就是为什么它不是”另一种 attention”,而是”把同一种 attention 跑得飞快”。
3. 主流 LLM 架构变体:选哪条路
到这里你已经知道了 Transformer 的核心机制。现在问题是:学术界和工业界是怎么基于这个骨架做选择的?
3.1 三种”主骨架”

你可以把当前所有主流 LLM 归到三大类:
第一类:decoder-only(只保留解码器)。 代表是 GPT 系列、Llama、Qwen、Claude、ChatGPT 背后的模型。这是今天最主流的路线,原因很简单——它的训练目标是”预测下一个 token”,这跟”对话生成”这件事天然匹配。
一个直觉:它就像一个只会”接话”的人——你给它上半句,它就能接下半句。ChatGPT、Copilot、文心一言、豆包,背后都是这一类。
第二类:encoder-only(只保留编码器)。 代表是 BERT。它擅长”理解”,不擅长”生成”——它把一段文字读进去,变成一个向量,但不擅长接着写。
直觉:它就像一个只会”听懂话”但不会说话的人。做文本分类、检索匹配、语义相似度判断时它很快、很便宜。你在搜索引擎里搜东西,背后很可能就跑着一个 BERT 类的模型。
第三类:encoder-decoder(编解码器都有)。 代表是 T5。适合”输入一段,输出另一段”的任务——翻译、摘要、结构化转换。它的训练目标是”看到输入 X,生成输出 Y”。
直觉:它像翻译官——左边听你说话,右边给另一群人翻译。
3.2 “优化外挂”:在不换主骨架的前提下加能力
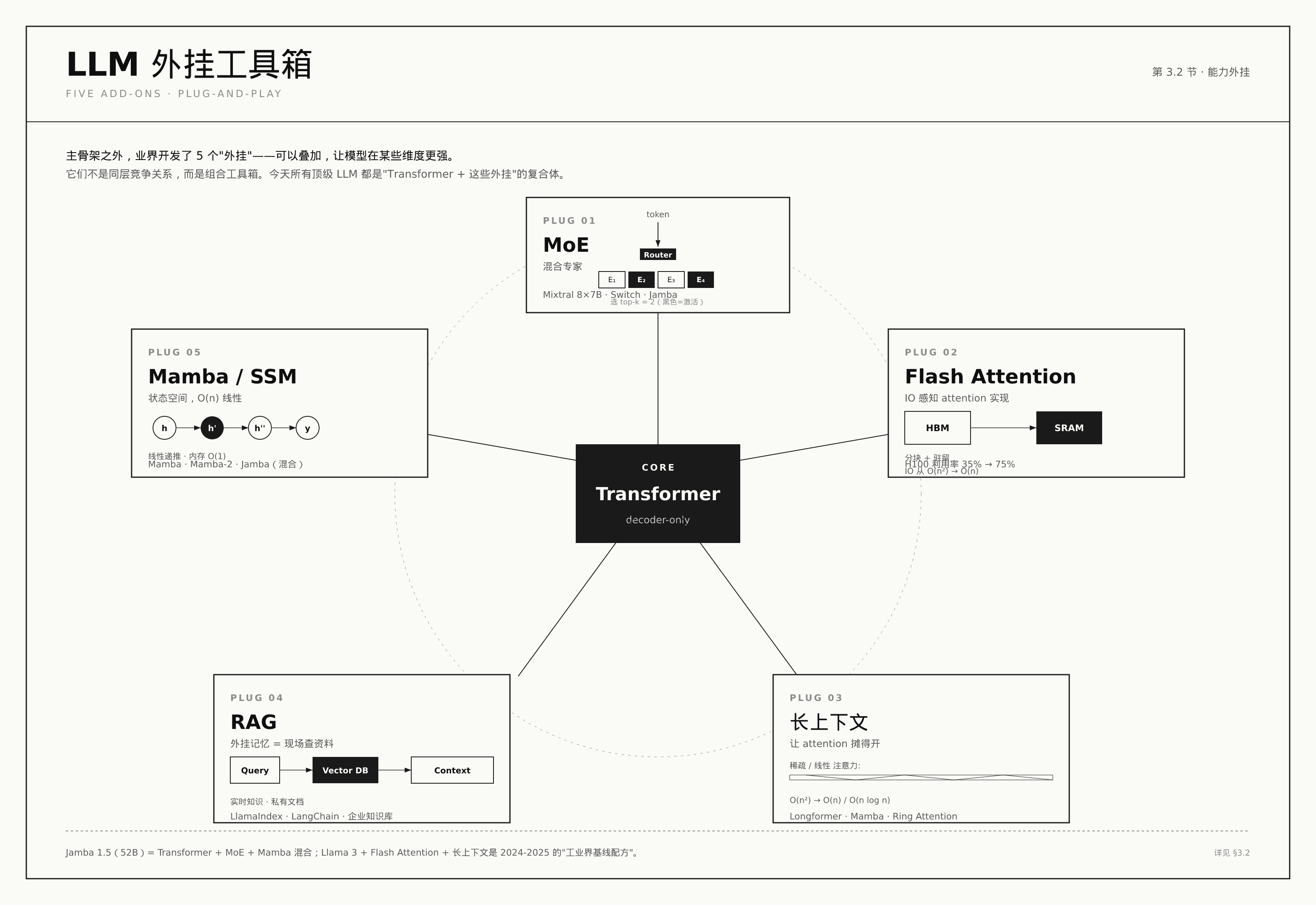
主骨架之外,业界还开发了一系列”外挂”,让模型在某些维度上更强。这些外挂可以叠加使用:
外挂 1:MoE(Mixture of Experts,混合专家)
传统模型是”一个大脑”——所有问题都让全部神经元参与计算。MoE 的思路是把”大脑”切成几个”专家小组”(比如 8 个),每个 token 进来时,路由器决定让哪 2 个专家来处理。
为什么这样做?在不增加推理成本的情况下扩大模型容量。
2024 年开源的 Mixtral 8x7B 是这个路线的代表:它总共有 470 亿参数,但每个 token 实际上只用 130 亿参数。这意味着你在消费级 GPU(比如 RTX 4090)上就能跑起来一个”接近 70B 模型能力”的模型,但推理成本只有 13B 模型的水平。
Jamba 1.5(AI21 Labs 2024)则把这个思路推得更远——它在 MoE 之上又叠加了 Mamba(状态空间模型),让 52B 参数的模型在单张 A100 GPU 上能装下 14 万 token 的上下文。
3.2.1 MoE 路由的数学形式(可跳过)
如果你想看 MoE 到底怎么”挑专家”:
是第 个专家的神经网络(通常就是一个 FFN), 是路由器学到的参数矩阵。
Switch Transformer(Google 2022)的关键简化:把 top-k 路由直接简化成 top-1,每个 token 只选一个专家。这让通信开销和工程复杂度大幅下降,效果却不输 top-2。
Mixtral 8x7B(Mistral AI 2024)的具体配置:8 个专家,每个 token 选 top-2。模型总参数量 467 亿,每个 token 实际只用 129 亿。
Jamba 1.5(AI21 Labs 2024)的混合设计:在 MoE 的 52B 总参数中,每个 token 实际激活 12B。更特别的是它每 8 层只有 1 层是 Transformer attention,其余是 Mamba 层——既利用了 attention 的全局检索能力,又利用了 Mamba 的线性复杂度优势。
外挂 2:RAG(Retrieval-Augmented Generation,检索增强生成)
传统模型的”知识”是冻结在参数里的——训练数据里有就是有,没训练过就不知道。RAG 的思路是:回答问题前,先去外部知识库(比如你公司的产品手册、最近的新闻)检索相关段落,把这些段落塞进 prompt,再让模型基于这些真实证据回答。
为什么这件事重要?因为模型参数无法实时更新。GPT-4 的训练数据有截止日期(2023 年某月),它不知道 2024 年发生的任何事。RAG 让模型”现场查资料”,相当于给一个记忆力很好、但只读过 2023 年报纸的学者,配了一个能联网的助理。
2024 年被称为”RAG 元年”——大量企业把内部文档(产品手册、合同、客服记录)灌进 RAG 系统,让 ChatGPT 这种通用模型能回答自家业务问题。这是一个非常成熟的工程方向,比”重新训练一个懂业务的大模型”便宜得多,也准得多。
外挂 3:长上下文扩展
让模型能”一次看更多内容”是 2023-2025 年的主战场。代表路线有:
- 稀疏 attention(Longformer、BigBird):不计算所有 token 两两之间的关系,只让”附近的 token”和某些”全局锚点 token”互相看,把 O(n²) 复杂度降到 O(n)。
- 状态空间模型 / Mamba(2023 年 12 月 CMU + Princeton 提出):完全换了一种思路,抛弃 attention,改用”循环状态”传递信息,理论上能做到 O(n) 的线性扩展。2024 年开始和 Transformer 混合使用。
- Flash Attention(Tri Dao 等 2022 年提出,2024 年第三代发布):这是工程层面的重大优化——它不改数学结果,但通过 IO 感知优化和分块计算,把 attention 的显存占用从 O(n²) 降到 O(n),速度提升 2-8 倍。今天几乎所有主流模型的训练和推理,背后都跑着 Flash Attention。
特别值得一提的是 Flash Attention。这不是”另一种模型”,而是一种”让现有模型跑得更快、显存更省”的实现技巧。它的作者 Tri Dao 在 2024 年发布的 FlashAttention-3 把 NVIDIA H100 的利用率从 35% 拉到 75%——这意味着你用同样一张 GPU,能训练更长的序列、跑更大的模型。这是工业界非常重要的工程胜利,但学术圈讨论得不多。
3.2.3 Mamba 的状态空间公式(可跳过)
状态空间模型(SSM)的核心是一个线性递推系统:
直觉:
- :第 时刻的输入
- :第 时刻的隐藏状态(相当于 RNN 的 memory)
- :模型学到的参数矩阵(对所有时间步共享)
- :第 时刻的输出
它像 RNN:每个时刻只更新状态 ,不存储过去所有时刻的信息。所以它的内存占用是 (只存 ),计算是 (线性扫描)。
Mamba(2023)的关键创新是把 (时间步长)变成输入相关的函数——也就是让 SSM 根据当前输入决定”我要不要记住这件事、要忘多少”。这让 SSM 第一次在语言建模上能匹敌 Transformer。
3.3 怎么选:决策树
如果你正在做一个具体项目,需要决定”用什么模型架构”或者”什么能力外挂”,下面是我整理的简化决策树:
- 任务是开放式对话、文案、代码生成 → decoder-only + 标准 attention。
- 任务是分类、搜索、匹配 → encoder-only(BERT 路线)或者小型 decoder-only + Embedding。
- 任务是翻译、摘要、结构化转换 → encoder-decoder。
- 需要便宜地跑超大模型 → MoE(如 Mixtral、Jamba)。
- 需要回答实时变化的知识 → RAG,不要重新训练模型。
- 需要处理超长文档 → 长上下文模型 + 合理的信息排布。
- 预算紧张但想要好效果 → 优先 Flash Attention 优化的开源模型(如 Llama 3、Qwen 2.5)。
4. 训练一个 LLM 大概是什么流程

这一节简单介绍,不展开——但你需要有个基本印象。
第一步:预训练。 用万亿级别的无标注文本(网页、书籍、代码),让模型学”预测下一个 token”。这个阶段最贵——GPT-4 级别模型的预训练据传花了数千万到数亿美元的电费。
第二步:监督微调(SFT)。 用人类写的”高质量示范”——比如”问题→好答案”对——继续训练。这一步让模型从”会接话”变成”会回答人话”。
第三步:指令微调(Instruction Tuning)。 用大量”按指令执行”的数据训练。FLAN、Tulu、OpenAssistant 这些公开数据集就是干这个的。这一步让模型从”会说人话”变成”听懂你让它做什么”。
第四步:RLHF(人类反馈强化学习)。 让人类对模型多个回答排序,用这些排序训练一个”奖励模型”,再用强化学习让基础模型朝”奖励模型打分高”的方向继续优化。ChatGPT 在这一步之后才真正”有用”——这一点都不夸张,OpenAI 公开报告说 1.3B 的 InstructGPT 在用户感受上能超过 175B 的 GPT-3 原模型。
一个对 Prompt 工程师很重要的认知:
很多你以为是”提示词写得好”的效果,其实是模型在训练阶段就已经学到的能力。
比如你写”请你以专家身份回答”——这之所以有效,不是因为提示词多么巧妙,而是因为模型在 RLHF 阶段见过无数”专家回答”的数据,知道这种语境下应该输出什么样的风格。提示词工程很重要,但它的天花板受限于模型的训练分布。
4.1 三个核心训练目标的数学形式(可跳过)
每种训练目标背后都是一个损失函数——模型学什么,由”它在最小化哪个损失”决定。
(1)Causal LM(自回归)—— GPT 系列的预训练目标
模型只学到当前 token 之前的内容,然后预测下一个 token。“因果”就是”不能偷看未来”,靠 causal mask 实现。
(2)Masked LM —— BERT 的预训练目标
随机遮住 个位置的 token,让模型根据上下文预测被遮住的部分。“双向”就是能同时看到左右两侧。
(3)Seq2seq / Denoising —— T5 的预训练目标
把原文 损坏成 (随机删词、换词、打乱顺序),让模型学会把 还原成 。这就是著名的 “span corruption”。
一个反直觉但重要的对比:causal LM 的损失函数最简单,但因为它是”逐字预测”,所以学到的能力最通用——这也是为什么今天几乎所有大语言模型都基于 decoder-only + causal LM 训练。
5. Prompt 工程:从”魔法咒语”到”接口设计”
好,到这里你理解了 LLM 内部在做什么。现在讲 Prompt 工程——这件事的本质不是”写漂亮话”,而是给模型计算过程一个外部接口规范。

5.1 几个核心概念
Zero-shot(零样本)
不举例,直接让模型做。
例子:
把以下句子翻译成英文:今天天气真好。模型能完成,是因为它在训练阶段见过海量”中英对照”数据。零样本适合简单、明确的任务。
Few-shot(少样本)
给几个示例,让模型”看样学样”。
例子:
任务:判断情感倾向。
示例1:
输入:这家店服务太差了,再也不来了。
输出:负面
示例2:
输入:服务员很热情,味道也好。
输出:正面
现在请处理:
输入:还行吧,没什么特别的。
输出:为什么这有效?2019 年 OpenAI 的 GPT-2 论文、2020 年 GPT-3 论文(Language Models are Few-Shot Learners)发现了一个神奇的现象:只要模型足够大,你给它 3-5 个示例,它就能”现场学会”这个任务——不需要重新训练。这就是 in-context learning(上下文内学习)。
实际工程含义:当你想让模型稳定地按某种格式输出(比如总是输出 JSON、总是按某种风格),给 2-3 个示例通常比写一段详细的描述更有效。
Chain-of-Thought(CoT,思维链)
让模型”先想一步,再给答案”。
普通提问:
问题:一个房间里 3 个人,又进来 5 个人,又走了 2 个人,最后有几个人?
答案:6加 CoT 后:
问题:一个房间里 3 个人,又进来 5 个人,又走了 2 个人,最后有几个人?
让我们一步步思考:
- 起始:3 人
- 进来 5 人:3 + 5 = 8 人
- 走了 2 人:8 - 2 = 6 人
答案:62022 年 Google 的论文 Chain-of-Thought Prompting 发现:对复杂推理题(数学、逻辑、规划),让模型先输出中间推理步骤,准确率能提升 30-50 个百分点。
但要注意:CoT 不是免费的——它让输出变长,所以推理成本变高。对简单任务(情感分类、命名实体识别)基本没用,对困难任务(数学题、复杂规划)效果显著。
ReAct(Reason + Act)
把”思考”和”行动”交替进行。
适合的场景是:模型需要查外部信息、调用工具、分步决策。
伪模板:
问题:{用户问题}
可用的工具:搜索(query)、计算器(expression)
请按如下循环工作:
Thought: 我现在需要知道 X
Action: search(X)
Observation: 搜索结果是 Y
Thought: 基于 Y,我还需要 Z
Action: calculator(Y + Z)
Observation: 计算结果是 W
Final Answer: 答案是 WReAct 是 2022 年 Princeton 和 Google 的论文 ReAct: Synergizing Reasoning and Acting in Language Models 提出的。它是现在所有”AI Agent”框架的雏形——Agent 的本质就是”一个会思考下一步要做什么、然后调用工具、然后再思考”的循环。
ReAct 的形式化表达(给想看算法骨架的朋友):
直觉:
- 是策略(policy),由语言模型扮演。
- = 当前状态(在 ReAct 里就是”对话上下文”)。
- = 当前动作(“调工具 X”、“计算 Y”、“问用户 Z”)。
- = 观察结果(工具返回值、用户回答)。
- = 思考-行动-观察的轨迹(trajectory),每一步都追加进上下文。
算法收敛条件通常是”模型决定输出 Final Answer”,或者”步数超过阈值”。
这就是今天所有 Agent 框架(LangGraph、AutoGen、CrewAI)的最小骨架。所有 Agent 都是在做”循环 + 工具调用 + 上下文追加”这件事——只不过不同框架的工程复杂度、容错机制、人机协作方式不一样。
System Prompt(系统提示词)
你在 ChatGPT 的”Custom Instructions”里写的那段话,就是 system prompt。
它的工程作用是稳定模型的行为边界——告诉模型”你是谁、你能做什么、不能做什么、回答用什么格式”。
一个好的 system prompt 通常包括这些元素:
角色:你是一名面向家长的儿童教育顾问。
约束:
- 用通俗易懂的语言,避免学术术语
- 不给医疗建议
- 如不确定,明确说"建议你咨询专业人士"
输出格式:
- 先给结论
- 再给 1-2 句解释
- 最后给一个具体建议为什么这个重要?Google 在 2024-2026 年的官方文档里反复强调:把关键行为约束、角色定义和输出格式要求放到 system prompt 或 prompt 的最前面。
一个反直觉但重要的发现:System prompt 不是越长越好。过长会挤压上下文窗口;冲突的指令(比如既要”详细”又要”简洁”)会让模型表现下降。短而清晰的约束比长而模糊的描述更有效。
System prompt 的位置权重(给想优化 prompt 的人):
直觉:LLM 对 prompt 中不同位置的”关注度”是不一样的。靠前、靠后的内容关注度最高,中间的关注度容易掉——这正是 Lost in the Middle 现象的形式化描述。
不同研究拟合出来的曲线不太一样(U 形、L 形、倒 L 形都有),但工程经验上是一致的:把关键约束放最前面、把最后问题放最末尾、中间放上下文材料。
5.2 真实世界的 Prompt 工程案例
抽象的概念讲完了,看几个真实使用场景。
案例 1:Cursor / Copilot 的代码补全
Cursor 是 2024-2025 年最火的 AI 代码编辑器之一。它背后的模型(GPT-4o、Claude 3.5 Sonnet)会”看到”你当前文件的全部代码、光标位置、最近修改——这些都是”上下文”。然后它基于这些上下文,预测你接下来要写什么。
Cursor 有一个 .cursorrules 文件——这是一个 system prompt 工程实践:你在项目根目录写一个文件,告诉 Cursor “这个项目用 TypeScript、命名用 camelCase、测试用 vitest”——模型会读这个文件,把它当成”项目级 system prompt”。
GitHub Copilot 也用类似的机制(.github/copilot-instructions.md),原理完全一样:给模型一个稳定的、不会随每次对话丢失的行为规范。
案例 2:ChatGPT 的记忆系统
OpenAI 在 2024 年 2 月推出”保存记忆”功能,2025 年 4 月升级为”自动从历史对话中提炼记忆”,2026 年 6 月又做了架构升级。
后台有一个叫 “Dreaming” 的进程——它在用户不在线时,自动从历史对话里”消化”出有用的信息,形成长期记忆条目。下次开新对话时,这些记忆会被自动注入到 system prompt 或上下文里。
OpenAI 公开数据说,这个升级让”事实回忆率”从 67.9% 提升到 82.8%,“用户偏好遵循度”从 55.3% 提升到 71.3%。
这背后的原理还是那个:模型本身没有长期记忆,但你可以用 system prompt + RAG 的方式给它造一个”外挂记忆系统”。
案例 3:企业 RAG 系统的真实踩坑
Reddit 上一个在制药、银行、律所做了 10 多个企业 RAG 项目的工程师总结过 10 大坑,我挑三个最有代表性的:
- 文档质量差到爆:他有个制药客户,手里 1995 年的研究论文是打字机打印再扫描的,OCR 几乎没法用;又混着 500 多页嵌满表格的现代临床报告。“对这两种文档用同一套分块策略,保证给你一坨乱码。”
- “只有 25% 企业真正获得价值”:很多企业上了 RAG,但回答质量差、不被使用。原因是没解决”我的业务里到底哪些问题适合让 AI 回答”。
- 企业文档不是知识库:客户手里的 1-5 万份 SharePoint 文档是”几十年积累的业务文档”,不是”AI 友好的知识库”。要做大量预处理(结构化、标签化、关联化)才能用。
这些案例说明:Prompt 工程不是写几段漂亮话,而是涉及文档处理、检索策略、上下文组织、输出验证的全链路工程。
5.3 Prompt 工程的实验设计纪律
最后讲一个很多人忽略、但非常重要的点:Prompt 调优必须有可复现的实验设计。
很多团队 prompt 调了很多轮,但实验根本不可复现,最后说不清”到底是 prompt 起的作用,还是换模型/换温度参数/换数据切分带来的”。
规范的实验设计应该控制这些变量:
- 模型版本固定(同一时间点的同一快照)
- 采样参数固定(temperature、top_p、max_tokens)
- 上下文预算对齐(不同方法给相近的 token 预算)
- 数据分层(按难度分桶抽样)
- 指标多维(准确率 + 格式正确率 + 延迟 + token 成本)
- 方差分析(few-shot 例子重采样至少 3-5 次)
- 事实性独立测(对知识题单独测幻觉率)
这条 discipline 在 2024-2025 年的 LLM 工程实践中越来越重要。Anthropic、OpenAI 的内部团队都在用类似的方法。
6. 一些对你继续学习有帮助的判断
到这里你应该对 LLM 有了一个相对完整的图景。最后留几个对你继续学习有帮助的判断:
第一,Transformer 仍然是 LLM 的基础语言。 不管是 GPT、Claude、Gemini、Llama、Qwen 还是最近很火的 Mamba 路线,本质上都在回答同一组问题:怎么更高效地组织注意力、参数、上下文和外部知识。
第二,架构选择本质上是任务和系统约束的映射。 你做开放生成,decoder-only 最自然;做理解检索,encoder-only 更经济;做条件生成,encoder-decoder 依然稳。MoE 解决容量效率,RAG 解决知识接入,长上下文机制解决 attention 成本——它们不是同层竞争关系,而是可以组合的工具箱。
第三,Prompt 工程真正有效的部分,不是花哨,而是结构化。 few-shot 是模式提示,CoT 是推理分解,ReAct 是工具耦合,system prompt 是行为边界。它们解决不同层面的问题,混着用时最忌讳”没有评测,只凭感觉”。
第四,context window 的工程重点不是”更长”,而是”更有效”。 没有好的 tokenization、检索、上下文排布与位置管理,单纯增大窗口很容易陷入”成本上涨但收益有限”的局面。Lost in the Middle 这个现象是真实存在的——把关键信息放在靠前或靠后位置是有数据支撑的。
第五,工业界和学术界正在快速融合。 Flash Attention 这类”工程优化”已经和模型架构本身一样重要;Mamba、MoE、RAG 已经被 ChatGPT、Claude、Gemini 这类顶级产品不同程度地采用。今天的 LLM 不是”一个 Transformer”——它是”Transformer + MoE + 长上下文优化 + Flash Attention + RAG + System Prompt + RLHF”等多种机制的复合体。
7. 进一步阅读
如果想深入,建议按这个顺序读一手资料:
- Vaswani et al., Attention Is All You Need(2017):Transformer 原点。注意不用背公式,看懂 attention 机制的直觉即可。
- Devlin et al., BERT(2018):理解双向编码和 MLM。
- Brown et al., Language Models are Few-Shot Learners / GPT-3(2020):理解 decoder-only 和 in-context learning。
- Raffel et al., T5(2020):理解 text-to-text 框架和 denoising 训练。
- Ouyang et al., InstructGPT(2022):理解 SFT → 奖励模型 → RLHF 的完整流程。
- Wei et al., Chain-of-Thought Prompting(2022):理解 CoT 何时真正有效。
- Yao et al., ReAct(2022):理解 reasoning 与 acting 的交替模式。
- Lewis et al., RAG(2020):理解参数记忆与非参数记忆的联合。
- Fedus et al., Switch Transformer(2022):理解 MoE 的工程价值。
- Tri Dao et al., FlashAttention-1/2/3(2022-2024):理解工程优化的重要性。
- Gu & Dao, Mamba(2023):理解 Transformer 之外的新路线。
如果只想读一篇综述性文章入门,Google Research 的 Attention Is All You Need 原文仍然是最值得读的——虽然它只是 2017 年的论文,但它的核心直觉和今天所有大模型一脉相承。
最后一句话:LLM 不是魔法,也不是骗局。它是数学、工程、产品三股力量在 2017-2025 这八年里持续叠加的产物。理解它的最好方式不是背公式,而是反复用、反复读它的输出、反复问”它为什么这么回答”。当你开始能预测”这个 prompt 会得到什么回答”、也能解释”为什么换个 prompt 结果就变了”,你就真正入门了。