写给要做 agent 选型 / 想理解今天框架到底在拼什么的人。我尽量不堆名词,但你需要的几个关键概念(ReAct、interleaved thinking、agent runtime、MCP、skills)我会讲到能讲出口的程度。
0. 一句话:今天的 agent 框架之争,已经不在 prompt 层,而在 runtime 层
先把结论摆在前面——这是 2026 年中这个时点最重要的一件事:
主流 agent 框架的竞争中心,已经从”会不会调用工具”转向”有没有可靠运行时”。
拉开差距的不再只是 prompting,而是会话持久化、权限控制、上下文压缩、技能复用、可恢复执行、MCP 互操作、多 agent 协作,以及和训练闭环结合的 RL/IL 体系。
这件事的工程含义是:同一个底座模型,放进 Claude Code、MiniMax Mavis、Hermes、OpenHands、LangGraph、AutoGen 这些不同 runtime 后,表现差异会比你想的大得多。这是 Anthropic 官方反复在文档里强调的事,也是真正选型时需要心里有数的事。
今天严肃的 agent 系统都在某种程度上组合了下面这几层:推理痕迹或”思维预算”机制、工具调用、规划与执行分离、记忆与技能层、状态化运行时、多 agent 分工、以及训练期的 imitation/reinforcement 优化。
但具体怎么组合——每家差别很大。后文会把 Claude Code、Mavis、Hermes 拆开看。
一个最近让我反复琢磨的数据:之前一份研究拆解 Claude Code 泄露的代码,发现真正属于模型决策的代码只有 1.6%,剩下 98.4% 全是管权限、管上下文、兜错的 harness。
换句话说:今天你看到的 Claude Code 强,不是因为它背后的 Claude 4.7 模型比 GPT-5.5 强多少——是因为那 98.4% 的”套在外面的壳”做得好。这条数据点把”prompt 时代结束,runtime 时代开始”这件事从口号变成了可量化的证据。
而 Mavis 在 2026 年 5 月发布 Agent Team 时打的旗号也是同一个东西——只不过他们把这层壳叫 “Team Engine”,把传统多 agent 的角色扮演换成了由状态机驱动的硬约束。
1. 概念边界:到底什么算 agent 框架
在选型之前,先把”agent 框架”这件事讲清楚——它不是泛指任何带工具调用的 LLM 应用。
Agent 框架 = 一类能在目标驱动任务中维持状态、调用外部环境、根据反馈迭代行动,并由运行时治理其权限、记忆、上下文与恢复机制的系统。
Anthropic 在 Claude Managed Agents 文档里把 agent 拆成四个核心概念:Agent、Environment、Session、Events。这其实就是今天工业界对 agent runtime 的共识。
翻译成人话:agent = 模型 + 运行时 + 环境接口 + 记忆 / 技能层 + 评估闭环。
这句话的反面更重要——agent 不是”会用工具的聊天框”。很多 LLM 应用确实”能调工具”,但它们没运行时、没恢复机制、没权限边界——那不叫 agent,叫 chatbot with tools。
你拿这条线去问任何一个 framework:它有没有运行时?有没有权限系统?能不能从中断恢复?有没有持久化的 session 和日志?四项都有才能叫严肃的 agent framework。
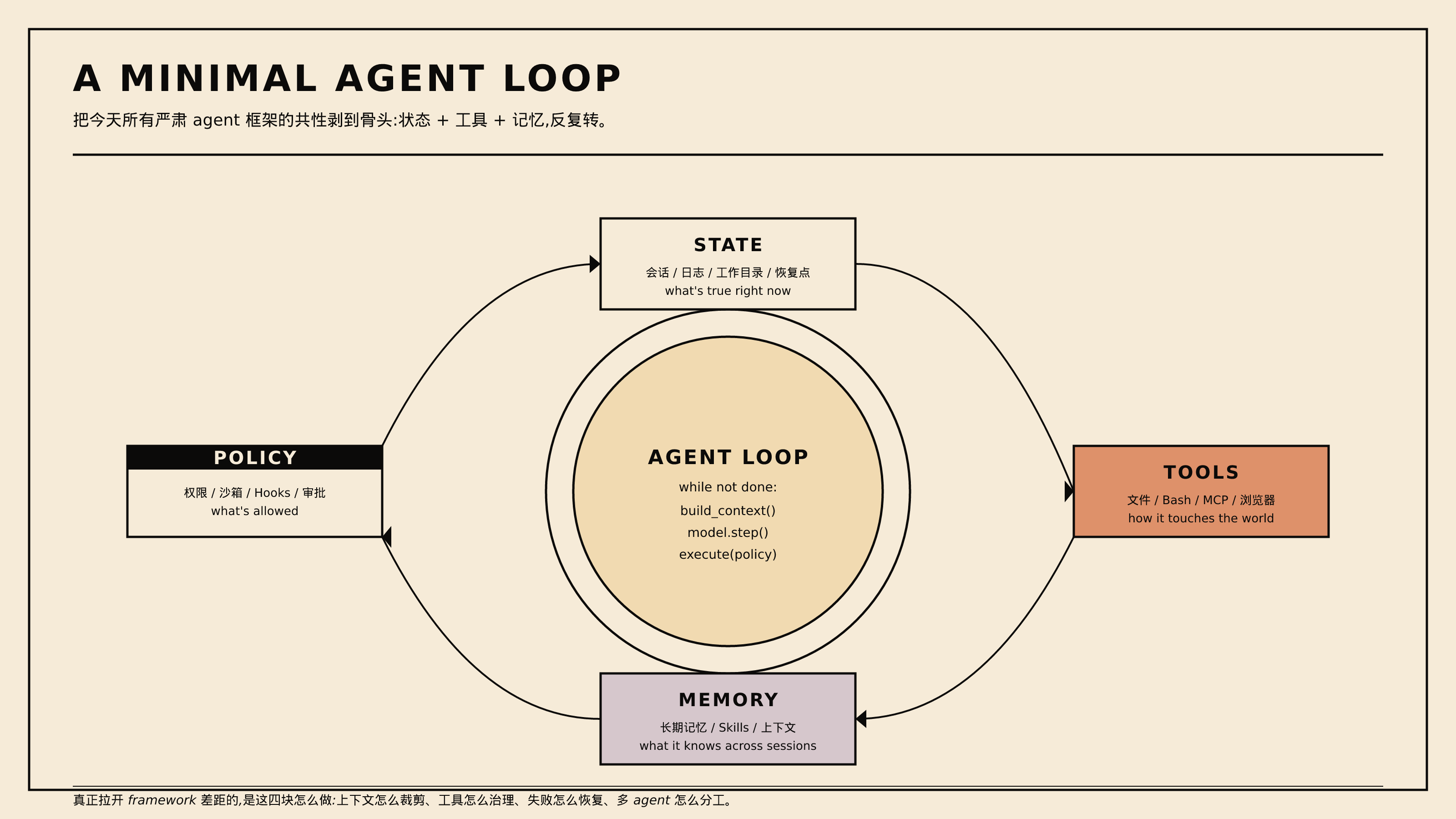
2. 一个最小可工作的 agent loop
下面这个图比任何抽象描述都直接。把今天所有严肃 agent 框架的共性剥到骨头——状态、工具、记忆、策略,反复发问转圈。
四块各自负责什么:
- STATE(状态):会话、日志、工作目录、恢复点。回答”现在是什么样”。
- TOOLS(工具):文件、Bash、浏览器、MCP server。回答”它怎么碰世界”。
- MEMORY(记忆):长期记忆、Skills、跨会话的上下文。回答”它长期知道什么”。
- POLICY(策略):权限、沙箱、Hooks、审批。回答”什么被允许”。
中间那个 while 循环就是大多数 framework 的核心:
while not state.done:
build_context() # 拼上下文
model.step() # 模型推理
execute(policy) # 按策略执行工具
observe_and_persist() # 记录 + 恢复点表面上简单到令人怀疑——这就是个 while 循环。但今天所有 framework 的真实差异,几乎都发生在下面四个细节上:
- 上下文怎么裁剪——长任务里这是头号问题。
- 工具怎么治理——谁能调、参数怎么校验、能不能拦截。
- 失败如何恢复——replan、checkpoint、retry 策略。
- 多 agent 如何分工——哪些任务值得拆、什么时候拆会亏。
学术和工业材料都表明,很多”agent 能力跃迁”其实来自这些细节,而不只是更强的 base model。
3. 推理与 chain-of-thought:从提示工程到训练对象
3.1 ReAct 是起点
2022 年那篇 ReAct 把”reasoning trace + action”合并到一个交替循环里——这是现代 language agent 的基石。它证明了一件事:在知识获取与环境交互任务中,把思考过程和行动过程耦合,能同时改善性能和可解释性。
紧接着 2023 年的 Reflexion 把”语言化反馈”和 episodic memory 引入 agent 学习循环:在不改权重的前提下,通过”反思文本”提升后续 trial 的决策质量。
这两件事的本质是同一个:让模型的中间推理变得可被记录、可被利用。
3.2 Interleaved Thinking:从推理痕迹到运行时机制
MiniMax 把这种思想工业化成了 interleaved thinking——模型输出里既有 reasoning_details,也有 tool_calls,而且官方文档专门提醒:多轮 function calling 时必须把 assistant 响应完整地放回历史中,以保持推理链的连续性。
这件事的意义比看上去大:CoT 在 agent 里不再只是提示工程,而开始成为训练对象和 runtime 对象。
Forge、M2.5/M2.7 的公开材料,正是把上下文管理直接纳入 RL 交互闭环来处理长任务里的”推理稀释”问题。传统思维链会被上下文膨胀吞掉——你 prompt 里塞了 50k token,真正相关的可能就 5k,但模型已经开始跑偏。
4. Tool-using 与 MCP:从偶尔有用的外挂到默认工作方式
从 Toolformer(2023)到今天的 function calling / MCP,主流工业系统已经把工具调用从”偶尔有用的外挂”变成了 agent 的默认工作方式。
但这里有个关键拐点——今天的差别不在”能不能调函数”,而在四个更细的事:
- 状态依赖:很多真实工具是有状态的(登录态、分页、光标位置),ToolSandbox 专门指出此前评测大多只覆盖无状态 REST,忽略了”隐式状态依赖”。
- 工具选择:给 agent 100 个工具,它怎么知道今天该调哪个?MCP 的资源 / 工具搜索机制就是为了解决这个。
- 权限边界:每个工具的调用方限制、参数校验、敏感操作拦截。
- 结果压缩与回放:工具返回可能很大,要压缩进上下文;失败要能重放。
4.1 MCP:标准化协议
MCP(Model Context Protocol) 是 Anthropic 提出的开放标准——把”怎么调外部工具”这件事从各家私有 API 拉回到统一协议。今天 Claude Code、MiniMax Mavis、Hermes 三家都支持 MCP。
这件事对工程选型的意义是:你的工具一旦按 MCP 暴露,可以被任何支持 MCP 的 agent 直接复用——不需要为每个 framework 写适配层。
但 MCP 也别神化。它解决的是”协议”,不解决”权限”和”安全”——那是 framework 的运行时层要做的。
5. Planner-Executor 与多 Agent:什么时候该拆
5.1 单体 ReAct 撑不住长任务
当任务步骤超过几轮后,单体 ReAct 往往不够稳。原因是:
- 上下文膨胀稀释了关键信息。
- 单个 agent 既当选手又当裁判会形成内在矛盾——你让模型”先做、再验证自己做的”,验证本身带着做事的偏差。
- 长链路的失败恢复成本线性上升。
于是有了 planner-executor、critic-refiner、researcher-writer-reviewer 这类结构化模式。
5.2 Voyager 和 MetaGPT 的两条经验
Voyager(2023)证明了一件事:在开放世界任务里,自动课程 + 技能库能让 agent 持续增长而不是一锤子买卖。这条思路直接影响了后来的 skills / memory 设计。
MetaGPT(2023)把 SOP 显式编码进多角色流水线,用”人类工作流”来降低级联幻觉。
5.3 真正难的两个问题
拆分的范式不稀奇,真正难的有两件事:
第一,拆分是否带来真实增益,而不是只放大 token 与协调成本。
把一个 agent 拆成五个,token 消耗可能涨 3-5 倍;如果拆分没有带来真正的能力提升,纯粹是在烧钱。
第二,验证器是否真的独立,而不是把同一个偏差复制两遍。
如果你的 reviewer 和 executor 用的是同一个模型 + 同一个上下文,所谓的”自我验证”只是复制偏差。
5.4 多 Agent 的工程判断准则
Mavis 在 Agent Team 长文里有一句非常值得拿来当判断准则的话:
多 agent 的核心不是”同时起多少个 agent”,而是为什么拆分、如何验证、何时停止、怎么恢复、怎样管理记忆。
如果这些问题没有清晰答案,多 agent 更像 demo 群聊,而不是生产系统。
实操上我会建议:只在任务复杂度足够、长程性足够、风险足够、经验可复用时再上多 agent。否则就是单 agent + 反思循环就够了。
6. RL 与 IL 集成:未来三年最重要的转向
这一节是 2025-2026 最重要、但也最容易被低估的转向。
APIGen 与 APIGen-MT 说明:高质量、可执行、可验证的工具使用数据,可以系统性提升 function-calling agent。
WebAgent-R1 证明:在多轮 web 环境中,端到端 RL 能把 3B/8B 模型的任务成功率大幅拉升。
MiniMax Forge 展示了工业界如何把 agent RL 规模化——试图同时解决吞吐、稳定性与 agent 自由度之间的”三难困境”,并显式支持任意 agent scaffold。
这意味着未来 agent 框架不会只是一层 inference-time scaffold。更现实的形态是:同一个 runtime 既是推理器,也是训练数据生成器、过程奖励承载体和评测执行器。
换句话说,runtime 正在成为基础设施层——和数据库、Web server 一样,今天不会有人去从头写一个数据库;但 2026 年还有大量团队在从头写 agent runtime。三年后这种局面大概率会收敛。
7. Claude Code:受控的 coding runtime
7.1 定位
Claude Code 是 Anthropic 的官方 agentic coding 工具,运行在终端、IDE、桌面应用与浏览器中。它能读代码库、编辑文件、跑命令、对接开发工具。Anthropic 的 Agent SDK 暴露了与 Claude Code 相同的工具、agent loop、上下文管理能力——这意味着 Claude Code 既是产品,也是 Anthropic 当前 coding agent runtime 的”参考实装”。
它的最强点不在”能写代码”这件事本身,而在工程现场的治理能力:
- 默认严格只读,额外动作需要审批
- Hooks 可拦截 / 放行 / 升级(基于 JSON 输出做决策)
- Skills 负责复用指令与命令
- Subagents / Teams 负责上下文隔离与并行拆分
- MCP 接外部工具
7.2 关键模块
Built-in Subagents(Explore、Plan 等)会在适当时候自动使用,每个 subagent 继承父会话的权限但会附加工具限制。
Hooks 允许在 Claude Code 生命周期的不同节点执行 shell 命令,并且不仅能发通知或格式化代码,还可以拦截受保护文件修改、重注入上下文、自动批准特定权限请求。更进一步,hook 可以通过 JSON 输出实现 allow / block / escalate 的细粒度决策控制。
MCP 方面,Claude Code 官方把它定义为连接外部工具和数据源的开放标准,支持导入、引用资源、工具搜索,以及把 Claude Code 本身作为 MCP server 使用。
Skills 文档说得很直接——skills 已经吸收了原有 custom commands 的使用方式,可以放在 .claude/skills/ 或兼容旧的 .claude/commands/ 路径里。
7.3 强项、局限与适用场景
强项:权限与安全设计成熟;与真实工程工具链耦合紧;可迁移性强——SDK 到 Managed Agents 一路打通。
局限:本体是商业条款下的 source-available,不是 OSI 开源;runtime 与 Anthropic 模型紧耦合(虽然可通过 MCP 接外部系统,但底层 agent runtime 并非 model-agnostic)。
适用场景:仓库级 coding agent、开发流程自动化、需要强治理的企业内部代理。
总结一句:如果你首要诉求是”稳定修 repo、跑命令、带审批、可观测、可接企业工具”,Claude Code 是非常稳的一条路。
7.4 开放状态
- 本体 Claude Code:source-available(商业条款),不是 MIT/Apache
- Agent SDK for Python:MIT
- Agent SDK for TypeScript:官方仓库
8. Mavis:产品级的”数字团队”
8.1 一个先说清的判断
“MiniMax 框架”在 2026 年并不是一个单一对象,而是一个由模型、产品、参考实现、技能库、MCP 接口与 RL 训练体系共同构成的生态。如果只盯着一个 repo,容易看错。
公开可拆解的部分大致有三层:
- 产品层:MiniMax Agent 在 2026 年 5 月整体升级后更名为 Mavis,并加入 Agent Teams
- 参考实现层:Mini-Agent、MiniMax Skills、MiniMax-MCP
- 模型与训练层:M2.5、M2.7、M3 与背后的 Forge agent-native RL
8.2 公开实现与产品运行时
Mini-Agent 官方文档把它定义为”用 MiniMax M3 构建 agents 的最佳实践演示”,README 还停留在 M2.5 版本。两者都强调 Anthropic-compatible API 与 interleaved thinking——说明它是 MiniMax 把前沿模型接入现有 coding / runtime 生态的桥梁。
它的公开特征非常完整:full agent execution loop、persistent memory、上下文自动总结、Claude Skills integration、MCP tool integration、详细日志。
这份 README 的含义很重要——MiniMax 不只是在讲”更强模型”,而是在给出可以落地复现的 runtime 架构骨架。
产品层的 Mavis 更偏向”长任务数字团队”。官方博客确认 Mavis 引入 Agent Teams,支持并行启动多个角色化 agents,在复杂任务上协作;文中还明确讨论了分工的四个上下文维度:不同 tools、不同 context、不同 memory、不同 skills,以及 pause/resume、人类介入和长期经验沉淀。
Agent Team 在 2026 年 5 月升级后的核心机制值得单独讲——它不再是传统多 agent 那种”提示词编排 + 角色扮演”,而是由 Team Engine 状态机驱动的硬约束。三类角色:
- Leader(Owner):拆解任务,决定派谁
- Worker:专业化执行,每个 worker 只看自己任务相关的上下文
- Verifier:独立核验 Worker 的交付。Verifier 与 Worker 是”对抗”关系——Worker 完成后必须交给 Verifier 独立核验;不通过就触发 Worker 返工修正,可以循环数十次
用户任务 → Leader 拆解 → Worker₁ / Worker₂ / Worker₃ 并行
↓
Worker 交付 → Verifier₁ / Verifier₂ / Verifier₃ 独立核验
↓ 不通过
Worker 返工修正(可循环数十次)
↓ 通过
Leader 汇总 → 用户这套对抗机制想解决的,是长程任务里两个出名的问题:上下文污染(一个 worker 抓到的错信息污染全队)和上下文焦虑(模型对”啥时候算做完”模糊判断,每完成一步就停下来确认)。实测中,APPSO 在一次活动策划任务里,Worker 和 Verifier 之间发生了数十次对抗,最终交付了 10+ 个产物文件,包括 xls、ppt、html 网页和对应 .md 版本——这种质量在传统多 agent 群聊里基本拿不到。
但代价也明摆着:多 agent 共识成本(Cost of Consensus)——交接成本、上下文摘要的存储分发、最终聚合成本加起来,token 消耗数倍于单 agent。MiniMax 自己也不回避这件事,给用户的建议是:Agent Team 是”贵且复杂”任务的策略选项,不是默认。
8.3 模型与训练范式
MiniMax 的生态最值得研究的一点,是它把agent training 与 product runtime 的相互塑形讲得非常清楚。
- M2.5:官方博文称经过”数十万复杂真实环境”的强化学习训练。
- M2.7:把”模型参与自己的自进化”与 agent harness 结合,让模型帮助更新记忆、构建技能并改善学习过程。
- Forge:尝试解决 agent RL 中 throughput / stability / flexibility 的三难冲突,支持任意 agent scaffold。
- M3(2026 年 6 月 1 日发布,距离本文写作 11 天):把 1M context、原生多模态、桌面操作能力合并到一个 open-weight 模型里。这套组合在 2026 年中之前只有 Claude Opus 4.7、Gemini 3.1 Pro、GPT-5.5 三家闭源模型集齐过——M3 是国产开源模型第一次拿到”前沿三件套”。
M3 的实测硬指标(截至 2026 年 6 月 1 日 SWE-Bench Pro 榜单):
| Benchmark | M3 | Claude Opus 4.7 | GPT-5.5 | Gemini 3.1 Pro |
|---|---|---|---|---|
| SWE-Bench Pro | 59.0% | 60.2% | 57.3% | 56.8% |
| Terminal Bench 2.1 | 66.0% | 62.3% | — | — |
| KernelBench Hard | 28.8%(开源最高) | — | — | — |
| OmniDocBench | 超过 Gemini 3.1 Pro | — | — | — |
在 Terminal Bench 2.1 上 M3 比 Opus 4.7 高 3.7 分——这件事比 SWE-Bench Pro 那个 1.2 分的差距更值得重视,因为它直接对应”真实终端命令执行 + 环境感知 + 错误恢复”的工程闭环。
Token Plan 价格也变了——这次合并 Token Plan + Agent Plan 为统一套餐:Plus 49 元/月(6 亿 token)/ Max 119 元/月(18 亿)/ Ultra 469 元/月(55 亿)。同价位段,Max 档是 Claude 订阅的约 15 倍用量。在 agent 时代,“模型变聪明但成本没人扛得住”这件事上,M3 这次第一次给出国产侧的解法。
这里最有研究价值的,是 MiniMax 把context management 当作训练对象,而不是纯 inference-time hack。上下文管理、记忆压缩、历史重写、deep think、多 agent 这些”黑盒 agent 行为”,都要能被 RL 系统兼容。
8.4 强项、局限与适用场景
强项:生态完整——产品、API、模型、技能、MCP、研究博客、RL 训练叙述是连起来的;长任务意识很强;对现实成本敏感(M2.5 发布材料把速度与价格直接放在 agent 场景里讨论)。
局限:公开实现与官方产品之间存在版本与命名漂移;大量性能数据目前主要来自厂商自报,独立学术复现实证相对少;产品级 Mavis runtime 本身仍主要以服务 / 产品形式交付。
适用场景:希望把 coding + office + multimodal + long-running automation 打成一体的 AI-native 团队;研究 agent RL、上下文管理与多 agent 产品化的研究工程团队。
总结一句:前者看 Mavis 与 MiniMax Code;后者重点看 Mini-Agent、Forge、M3 和 MiniMax-MCP。
8.5 开放状态
- 产品层 Mavis:服务化交付
- 公开实现:Mini-Agent / Skills / MCP 都是 MIT
- 模型层:混合态(M3 为 open-weight)
9. Hermes:开源的长期数字同事
9.1 定位
Hermes Agent 是 Nous Research 推出的开源 agent runtime。最鲜明的定位不是”另一个 coding CLI”,而是一个能长期工作、跨会话积累、可通过多种消息通道常驻运行的自改进代理。
官方 README 直接称它为”the self-improving AI agent”,强调 built-in learning loop、技能生成与改进、过去会话搜索、逐步加深的 user model。它既能作为终端交互工具运行,也能通过 gateway 接入 Telegram、Discord、Slack、WhatsApp、Signal、Email 等渠道。
对比定位:
- Claude Code = 有纪律的 coding runtime
- Mavis = 产品级数字团队
- Hermes = 可部署在 VPS 或云端、持续记住你与项目、并逐步学会流程的个人 / 团队操作代理
9.2 关键模块
Skills 是 Hermes 最强的结构件。官方文档明确说:skills 是给 Hermes 添加新能力的首选方式,因为相比新写 tool,它们更容易创建、不需要修改 agent 代码、而且可以共享到社区。每个已安装 skill 自动成为 slash command;系统采用 progressive disclosure,需要时才加载技能全文。
Memory 既有内建 MEMORY.md / USER.md 记忆机制,也支持 OpenViking、Mem0、Hindsight、RetainDB 等外部 memory providers。官方 memory provider 文档说明:当启用外部 provider 时,Hermes 会在每轮对话前预取相关记忆、在会话后同步对话、镜像内建记忆写入,并为 provider 增加专用工具。
Context files 与常驻化:AGENTS.md 在会话启动时自动注入,SOUL.md 持久化人格风格,.cursorrules 也兼容。Hermes 带内建 cron scheduler,可以把自动化任务投递到不同平台。
9.3 强项、局限与适用场景
强项:MIT 开源,便于二次开发与私有部署;memory-first、skills-first,适合长期个体代理或团队内常驻 bot;模型提供方弹性高——官方 Quickstart 与 Tips 都强调 provider 可切换,Portal 模式甚至提供 300+ models;通道天然多样,可以从 Telegram 等平台直接驱动。
局限:工程复杂度会转移到配置侧——memory provider、toolsets、gateway、portal、cron、container isolation 一起出现时,对团队运维能力有要求;公开材料更多强调 architecture 与 feature docs,而不是统一 benchmark leaderboard。
适用场景:长期个人研究助理、团队运维 / 消息机器人、需要 memory + skill accumulation 的私有化代理。
9.4 开放状态
Hermes Agent 仓库是 MIT license;Skills Hub、Memory、Cron、MCP、Gateway 文档都比较完整。
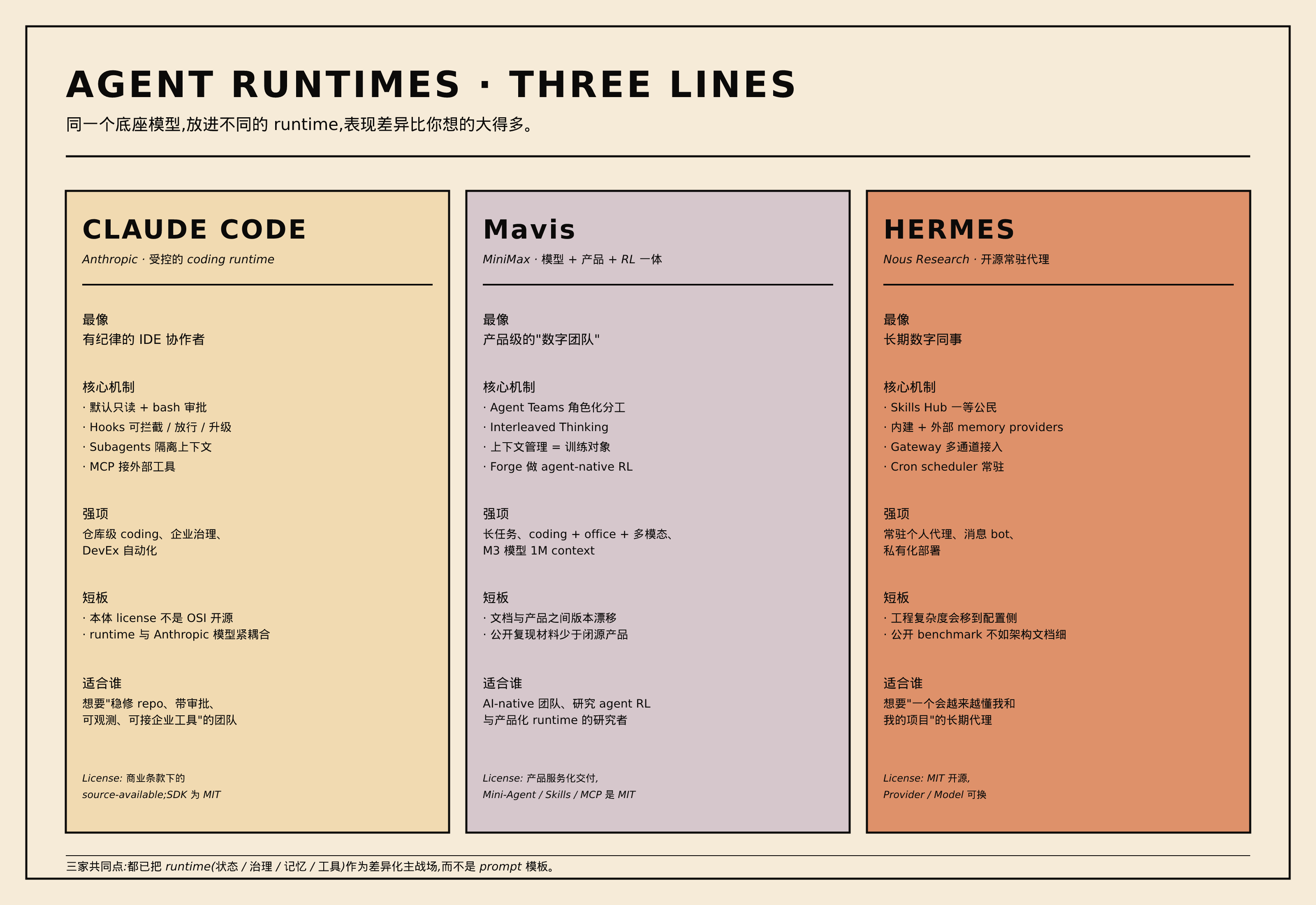
10. 三家对比与选型建议
把三家放进同一张图看:
| 维度 | Claude Code | Mavis | Hermes |
|---|---|---|---|
| 最像 | 有纪律的 IDE 协作者 | 产品级数字团队 | 长期数字同事 |
| 核心机制 | Hooks + Subagents + MCP(98.4% 的代码是 harness) | Team Engine + Leader-Worker-Verifier 对抗式 + M3 模型 | Skills + Memory + Gateway + Cron |
| 强项 | 仓库级 coding、企业治理 | 长任务、coding + office + 多模态 | 常驻代理、私有化、多通道 |
| 短板 | license 非 OSI 开源、与 Anthropic 紧耦合 | 多 agent 共识成本高、是”贵且复杂”任务的选项 | 工程复杂度转移到配置侧 |
| License | 商业条款 source-available;SDK 为 MIT | 产品服务化;Mini-Agent/Skills/MCP 是 MIT;M3 是 open-weight | MIT 开源;Provider / Model 可换 |
| 适合谁 | 想要”稳修 repo、带审批”的工程团队 | 想把 coding + office + 多模态打通的 AI-native 团队 | 想要”会越来越懂我”的长期代理 |
三家共同点:都已经把 runtime(状态 / 治理 / 记忆 / 工具)作为差异化主战场,而不是 prompt 模板——harness 占比的 98.4% 就是这事最直接的证据。
三家分歧:
- Claude Code 押注”工程治理”——权限、hooks、subagents 这条线;偏开发者工具
- Mavis 押注”产品化长任务”——Team Engine 状态机 + M3 模型 + 多通道接入(微信/飞书);偏产品级数字团队
- Hermes 押注”开源常驻记忆”——skills-first、memory-first、多通道;偏长期个人/团队代理
你选哪家,本质是问:你想要一个”有纪律的协作者”、“一个产品级数字团队”、还是一个”长期数字同事”?
11. 学术证据与论文推荐
如果你想从源头理解,ReAct → Reflexion → SWE-agent → AgentBench / WebArena / OSWorld / ToolSandbox → GAIA / BrowseComp / TheAgentCompany → WebAgent-R1 / APIGen / Forge → OAgents / AI Agents That Matter。
这条阅读路径的设计意图:先得到”框架原型”,再得到”环境与评测”,最后才是”训练与批判性再评价”。
几个关键人物值得跟:
- Shunyu Yao:ReAct、Reflexion、SWE-agent 一脉的重要作者,近年在 OpenAI 做 CUA / Deep Research 方向。长文《The Second Half》很值得读。
- Karthik Narasimhan:Princeton 语言智能主线学者,对 ReAct、Reflexion、SWE-agent 体系影响极大。
- Graham Neubig:WebArena、TheAgentCompany、OpenHands 等方向的关键人物。
- Frank F. Xu:TheAgentCompany、API-based Web Agents 等工作的核心作者。
11.1 评测的两条硬经验
读到这里你会发现,框架的差异最终还是要落到评测上。两条硬经验:
第一,成本归一化还远不够。若不控制成本,简单 baseline 甚至可能胜过复杂 agent 架构;很多所谓 agent 增益,实际上可能只是”多采样 + 更多 token + 更多重试”的结果。
第二,复现实验协议缺失。过去大量开源工作由于缺乏统一协议、随机种子控制和稳健比较,结果方差很大。
工程上的硬建议:把 success、cost、latency、tool count、human intervention rate、recovery rate 一起记录。只盯”成功率”会让框架选择失真。
12. 趋势:未来三年高概率发生的事
12.1 短期:runtime 成为基础设施
Anthropic 把 Managed Agents 明确定位为长时间运行、异步任务用的托管 agent harness;MiniMax 把控制平面、事件日志、状态恢复、人机协作与 multi-agent runtime 放到产品核心;Hermes 在开源侧把 memory、skills、gateway、cron、context files 并列为一等公民。
以后真正的框架差异,会越来越体现在 runtime 层,而不是 prompt 层。
12.2 中期:RL/IL 与 runtime 融合
APIGen、APIGen-MT、WebAgent-R1、Forge 都在说明,agent 不再只是推理期策略,而是训练期的可优化对象。能够生成过程信号、保存交互轨迹、执行统一 benchmark harness 的 runtime,会逐渐比”只会调用模型”的 orchestration 库更有护城河。
12.3 长期:少量高质量多 agent + 长期记忆 + 可验证执行 + 多模态环境
OSWorld、GAIA、BrowseComp、TheAgentCompany 这些基准共同指向:只要任务足够长、跨模态、跨工具、跨文件系统,单纯靠”大上下文 + 一次规划”仍然不够。未来更可能出现的是结构化、小规模、带审计的 agent 团队,而不是任意数量 agent 的开放群聊。
12.4 五块研究空白
- 长期记忆收益如何评测——目前仍缺统一协议
- Skills 的生成、检索、退化与版本控制——缺乏标准 benchmark
- 权限、安全、合规——虽然工业部署核心,却远少于 planning / tool-use 那样被系统评测
- 多 agent ROI——仍缺成本归一化的严格证据
- 开放框架与闭源产品之间的可比性——运行时、工具、预算和 stopping criteria 常常不一致
13. 一条实用学习路径
最省时间的路径不是”先把所有论文看完”,而是下面这条:
- 用 Claude Code / Mini-Agent / Hermes 各跑一个最小任务——体会三种 runtime 差异
- 用 LangGraph 或 AutoGen 自己复刻一个 planner-executor + memory + MCP 小系统——理解可编排图与多 agent 抽象
- 在 WebArena / SWE-bench / ToolSandbox 上做一次严格、固定预算的 ablation——把”成本归一化”刻进肌肉记忆
- 再决定你真正要攻的方向:上下文管理、知识记忆、工具治理、多 agent 拆分、还是 RL 训练
对工程团队,我给一个更实用的三段式建议:
- 第一阶段:用 Claude Code、Mini-Agent 或 Hermes 在明确边界的小任务里建立成功经验
- 第二阶段:把 memory、MCP、hooks、审计、回滚、工作目录隔离、人工 checkpoint 补齐
- 第三阶段:只有在你能稳定记录成本和收益后,再引入 agent teams 或 RL 数据闭环
最后一句话:选 framework 不是选 model,是选未来三年你要不要为 runtime 付钱。今天 runtime 的差异还没有完全显化——但 2027 年回头看,差距会是数量级的。