深入理解 Claude Code 设计原则(一):项目全局认知与资源导航

本系列共四篇,基于 VILA-Lab 的论文 Dive into Claude Code: The Design Space of Today's and Future AI Agent Systems 整理。这是第一篇,聊聊这个项目的来龙去脉,Claude Code 的整体架构长什么样,以及你应该去哪里找进一步的资料。
深入理解 Claude Code 设计原则 · 系列导航
这个项目是怎么来的
2026 年 3 月底,Claude Code 的 TypeScript 源码被意外泄露到了 npm。这件事在开发者社区引起了不小的震动。Alex Kim 写的第一篇分析文章在 Hacker News 上迅速走红,随后各路人马开始对这约 512K 行、1,884 个文件的代码库进行逆向分析。
社区里很快出现了两类工作。一类是工程导向的:把源码反混淆、重新构建出可运行版本,甚至用 Rust 重写(claw-code 在 9 天内拿到了 179K 个 GitHub 星标,成为有史以来最快突破 100K 星的仓库)。另一类是分析导向的:博客文章、技术 deep-dive、逆向工程报告。
VILA-Lab 的这篇论文走了第三条路。他们没有停留在"这个模块做了什么"的层面,而是试图回答一个更根本的问题:Claude Code 为什么这么设计? 他们提出了一个"价值观 → 原则 → 实现"的分析框架,把每一个源码级的设计选择都追溯到背后的人类价值观。
论文发表在 arXiv(论文编号 2604.14228),分析的是 v2.1.88 版本的 Claude Code。
98.4% 的代码不是 AI
先说这个项目里最让人意外的发现。
Claude Code 代码库里真正涉及 AI 决策的逻辑,只占约 1.6%。剩下的 98.4% 全是确定性的基础设施代码:权限检查、上下文压缩、工具路由、错误恢复、会话持久化。
Agent 循环本身就是一个 while 循环。就这么简单。模型被调用,返回结果,如果结果里包含工具调用就执行对应的工具,然后继续循环。整个 queryLoop 的核心逻辑用伪代码写大概十几行就够了。
那工程复杂度在哪?在循环 周围 的那些系统。每次调用模型之前,有 5 层压缩策略依次运行,确保上下文窗口不超限。每次工具执行之前,要经过 7 层安全检查。权限系统有 7 种模式,从完全锁定到几乎不管。还有 27 种钩子事件可以让外部代码干预 Agent 的行为。
这个比例让我反复想了很久。我们讨论 AI Agent 的时候,注意力大多放在模型选择、prompt 工程、推理能力上。但 Claude Code 的数据告诉你,一个生产级 Agent 系统里,这些东西大概只占 2% 的工作量。另外 98% 是基础设施。
七个组件,五个层次
Claude Code 的整体结构可以拆成 7 个组件:
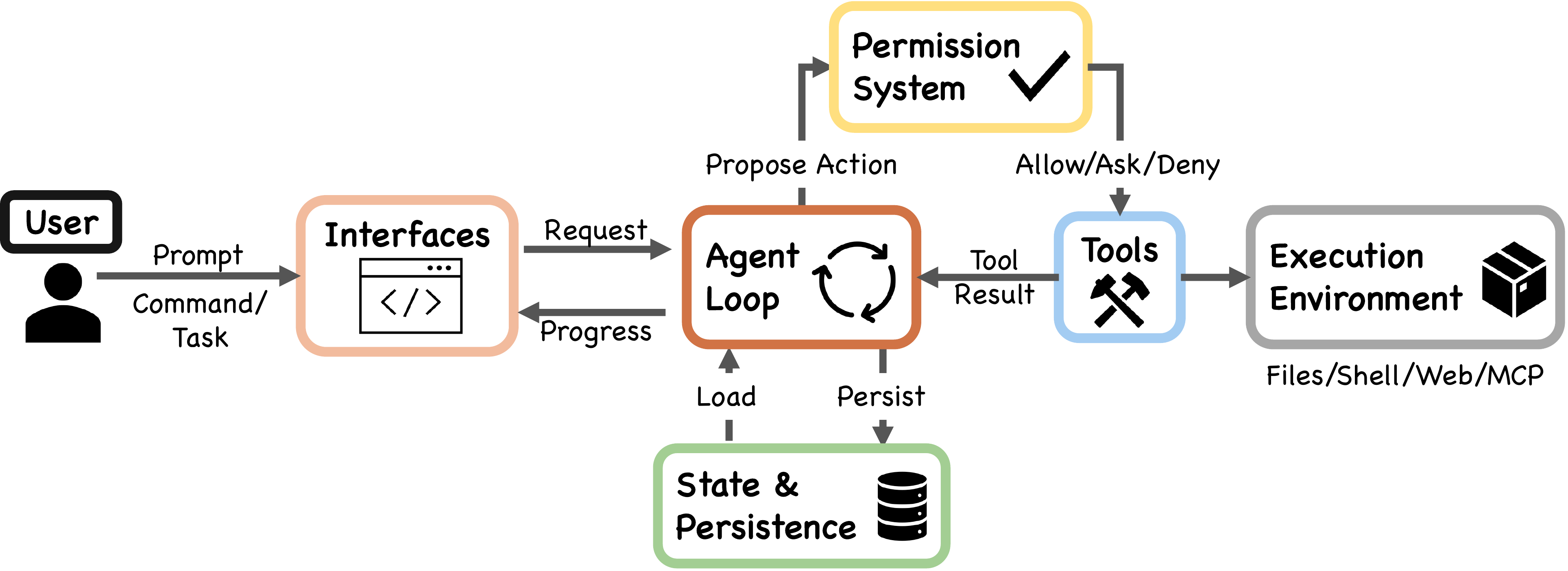
- 用户 - 发 prompt,批准权限,看结果
- 入口层 - 交互式 CLI、无头 CLI(
claude -p)、Agent SDK、IDE 插件,四种入口共用同一个执行引擎 - Agent 循环 -
query.ts里的queryLoop,一个 AsyncGenerator 驱动的 ReAct 循环 - 权限系统 - deny-first 规则 + auto 模式的 ML 分类器 + 钩子拦截
- 工具层 - 最多 54 个内置工具 + MCP 服务器提供的外部工具
- 状态与持久化 - append-only 的 JSONL 会话日志、prompt 历史、子 agent 侧链
- 执行环境 - Shell(带沙箱)、文件系统、网络请求、MCP 连接
这里有个值得注意的设计选择:所有入口(CLI、SDK、IDE)最终都走同一个 queryLoop。不存在"CLI 模式用这套逻辑,IDE 模式用另一套"的情况。
把这 7 个组件按职责分层,形成 5 层架构:
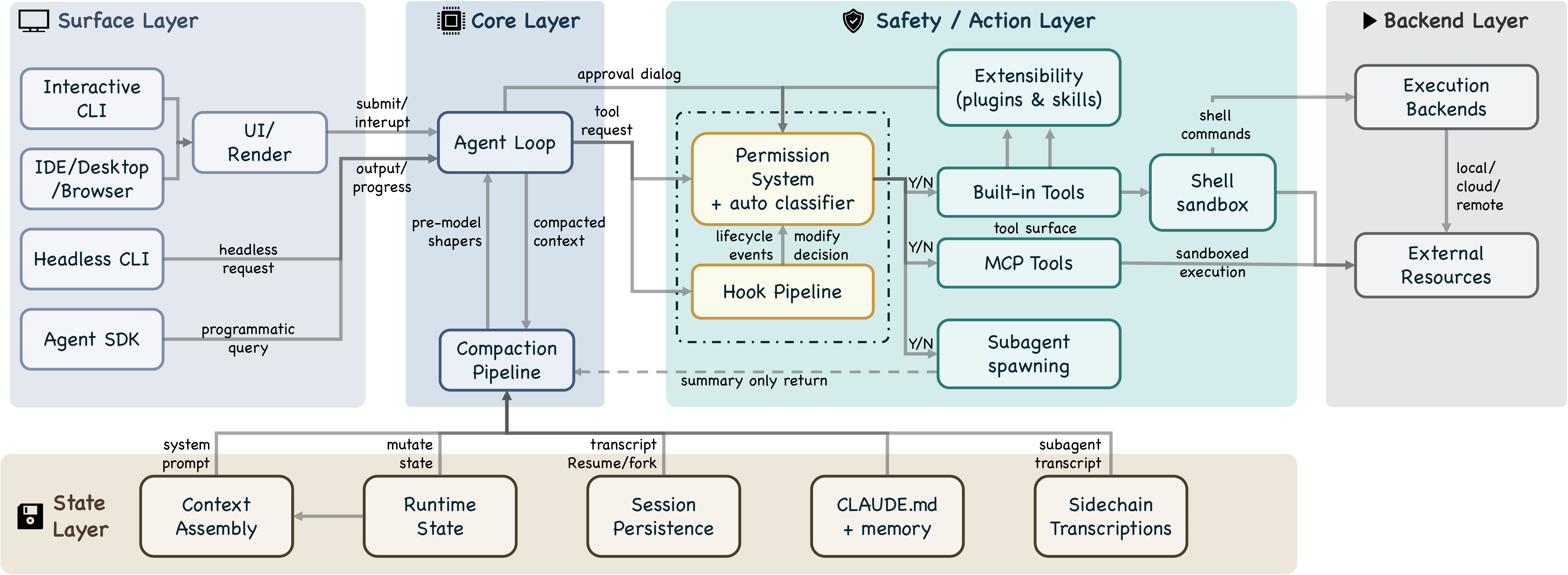
| 层级 | 职责 | 主要组件 |
|---|---|---|
| Surface | 入口和渲染 | CLI, headless, SDK, IDE(用 React + Ink 做终端 UI) |
| Core | 上下文组装和 Agent 循环 | queryLoop, 5 层压缩管道, 子 agent 派生 |
| Safety/Action | 权限和工具 | 7 种权限模式, auto 模式分类器, 27 个钩子事件, 工具池, shell 沙箱 |
| State | 运行时状态和持久化 | JSONL 日志, CLAUDE.md 层级, 自动记忆, 侧链文件 |
| Backend | 执行环境 | Shell 执行, MCP 连接(7 种传输方式), 42 个工具子目录 |
五个价值观和十三条设计原则
论文最有意思的部分之一,是它提出了一个自上而下的分析框架。不是从代码出发问"这段代码做了什么",而是从价值观出发问"为什么要这么设计"。
Claude Code 的设计可以追溯到 5 个人类价值观:
| 价值观 | 它在实际系统里意味着什么 |
|---|---|
| 人类决策权威 | 人类通过"主体层级"保持控制权。Anthropic 发现 93% 的权限提示被用户直接批准(根本没仔细看),他们的应对不是加更多弹窗,而是用沙箱和分类器重新划分边界 |
| 安全 | 即使人类走神了,系统也要守住底线。7 层独立安全防护 |
| 可靠执行 | 按用户的意图而不是字面意思去做事。收集信息、执行操作、验证结果的闭环 |
| 能力放大 | Anthropic 把 Claude Code 定位为"Unix 工具"而不是"产品"。98.4% 的代码都是为了让那 1.6% 的 AI 逻辑能好好工作 |
| 上下文适应性 | 用 CLAUDE.md 层级让不同项目有不同的配置,用渐进式信任让权限随使用时间演变 |
从这 5 个价值观派生出 13 条设计原则(完整列表见下一篇文章),再从原则落地到具体的代码实现。这种追溯关系是论文的分析骨架。
论文还引入了一个额外的评估维度:长期能力保持。他们引用了一项研究,发现在 AI 辅助条件下工作的开发者在代码理解测试中得分低 17%。这不是一个容易消化的数字。
资源导航
下面是围绕 Claude Code 架构的各类资源。我按照"从哪里开始读"的逻辑做了排列。
官方来源
Anthropic 自己发布的工程博客和产品文档,是理解设计意图的第一手资料。
工程与研究博客:
| 文章 | 你能从中学到什么 |
|---|---|
| Building Effective Agents | Anthropic 的 Agent 设计哲学:简单的可组合模式比重型框架好 |
| Effective Context Engineering for AI Agents | 上下文管理的思路。为什么要跑 5 层压缩 |
| Harness Design for Long-Running Application Development | 长时间运行的 Agent 系统怎么设计 harness |
| Claude Code Auto Mode | auto 模式的 ML 分类器是怎么工作的 |
| Beyond Permission Prompts | 沙箱安全方案。权限提示减少了 84% |
| Measuring AI Agent Autonomy in Practice | 自动批准率随用户经验增长的纵向数据 |
| Scaling Managed Agents | 推理、执行、会话分离的托管服务架构 |
产品文档:
| 文档 | 覆盖什么 |
|---|---|
| How Claude Code Works | Agent 循环、工具、终端自动化的官方说明 |
| Permissions | 权限系统的完整参考 |
| Hooks | 27 个钩子事件的参考文档 |
| Memory | CLAUDE.md 层级和记忆系统 |
| Sub-agents | 子 agent 的使用方式 |
社区架构分析
| 仓库 | 特点 |
|---|---|
| ComeOnOliver/claude-code-analysis | 源码树结构、模块边界、工具清单、架构模式 |
| alejandrobalderas/claude-code-from-source | 18 章技术书(约 400 页),用原创伪代码写的 |
| liuup/claude-code-analysis | 中文。从启动流程到查询主循环到 MCP 集成 |
| sanbuphy/claude-code-source-code | 四语分析(中英日韩),75 份报告 |
| Yuyz0112/claude-code-reverse | 可视化工具,追踪 API 调用的 prompt 和 tool call |
| AgiFlow/claude-code-prompt-analysis | 5 个 session 的完整 API 请求/响应日志 |
开源重新实现
| 仓库 | 特点 |
|---|---|
| ultraworkers/claw-code | Rust 重写,512K 行压到约 20K 行,9 天 179K 星标 |
| chauncygu/collection-claude-code-source-code | 聚合仓库,收集多个重新实现版本 |
| 777genius/claude-code-working | 可运行的逆向工程 CLI,polyfill 了 31 个特性标志 |
| T-Lab-CUHKSZ/claude-code | 中文大学(深圳)的研究分支 |
| ruvnet/open-claude-code | 每晚自动反编译重建,903 个测试 |
| Enderfga/openclaw-claude-code | 统一 ISession 接口,多后端支持 |
教程和学习路径
| 仓库 | 特点 |
|---|---|
| shareAI-lab/learn-claude-code | 19 章从零课程,带可运行的 Python Agent 代码 |
| FlorianBruniaux/claude-code-ultimate-guide | 从入门到进阶的指南,有生产级模板 |
| affaan-m/everything-claude-code | Agent harness 优化技巧,50K+ 星标 |
| nblintao/awesome-claude-code-postleak-insights | 泄露后资源的最佳整理 |
博客文章
源码泄露前的逆向分析:
| 文章 | 为什么值得读 |
|---|---|
| Marco Kotrotsos 的 15 部分系列 | 泄露前最系统的分析,基于 v2.0.76 |
| George Sung 的 LLM 流量追踪 | 完整系统 prompt 和 API 日志 |
| Kir Shatrov 的逆向工程 | mitmproxy 截获 API 调用,40 秒/$0.11 |
源码泄露后的分析:
| 文章 | 为什么值得读 |
|---|---|
| Alex Kim 的泄露分析 | 第一手报道,反蒸馏机制、Undercover Mode |
| Haseeb Qureshi 的跨 Agent 对比 | Claude Code vs Codex vs Cline vs OpenCode |
| MindStudio 的三层记忆架构 | 记忆系统写得最好的一篇 |
| Agiflow 的 prompt 增强逆向 | 5 种 prompt 增强机制 |
学术论文
| 论文 | 你能从中学到什么 |
|---|---|
| Decoding the Configuration of AI Coding Agents | 分析了 328 个 Claude Code 配置文件 |
| On the Use of Agentic Coding Manifests | 253 个 CLAUDE.md 文件的结构模式 |
| OpenHands (ICLR 2025) | 开源 AI 编码 Agent 的学术参考 |
| SWE-Agent (NeurIPS 2024) | Docker 隔离 + 自定义 ACI |
| A Survey on Code Generation with LLM-based Agents | AI 编码 Agent 领域综述 |
其他 AI Agent 项目
| 项目 | 设计路线 |
|---|---|
| sst/opencode | 不绑定模型厂商的终端编码 Agent |
| HKUDS/OpenHarness | 开放 Agent harness,学术方向 |
| coleam00/Archon | 确定性路线:YAML 工作流 + 执行审计 |
| openai/symphony | OpenAI 的编排方案,并行会话设计 |
小结
这个项目的价值不在于告诉你"Claude Code 有什么功能"。你如果日常在用它,功能你比论文作者还熟。它的价值在于回答"为什么"。
为什么 Agent 循环这么简单?因为 Anthropic 赌模型能力会持续提升,所以把投入放在了确定性的 harness 上,而不是复杂的推理脚手架。为什么权限系统这么复杂?因为他们发现用户会对 93% 的提示直接点批准,所以"多问几次"这条路走不通,需要用结构化的方式重新划边界。为什么记忆不用向量数据库?因为他们选择了透明性和可编辑性,而不是检索精度。
每一个设计选择背后都有一个 tradeoff。后面三篇文章会逐一展开。
下一篇:核心机制深潜
评论